2011년 10월 2일 일요일
큐
큐(Queue) 란?
큐(queue)는 컴퓨터의 기본적인 자료 구조의 한가지로, 먼저 집어 넣은 데이터가 먼저 나오는 FIFO (First In First Out)구조로 저장하는 형식을 말한다. 영어 단어 queue는 표를 사러 일렬로 늘어선 사람들로 이루어진 줄을 말하기도 하며, 먼저 줄을 선 사람이 먼저 나갈 수 있는 상황을 연상하면 된다.
나중에 집어 넣은 데이터가 먼저 나오는 스택과는 반대되는 개념이다.
프린터의 출력처리나 윈도우 시스템의 메시지 처리기, 프로세스 관리 등 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에 이용된다.
출처: http://ko.wikipedia.org/wiki/%ED%81%90_(%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0)
라고 쓰여 있다.. 암튼 먼저 입력한넘부터 출력하기 좋은 자료구조란다.
2. 완전 간단 구현 큐 소스
뭐 어찌 보면 링그드리스트와 비슷한거 같기도 하고.
암튼 그냥 선형큐 는 오버플로 가 날 문제를 안고 있는 구조라 하니 조금 수정된 원형큐로 해보자...
3. 원형큐
큐(queue)는 컴퓨터의 기본적인 자료 구조의 한가지로, 먼저 집어 넣은 데이터가 먼저 나오는 FIFO (First In First Out)구조로 저장하는 형식을 말한다. 영어 단어 queue는 표를 사러 일렬로 늘어선 사람들로 이루어진 줄을 말하기도 하며, 먼저 줄을 선 사람이 먼저 나갈 수 있는 상황을 연상하면 된다.
나중에 집어 넣은 데이터가 먼저 나오는 스택과는 반대되는 개념이다.
프린터의 출력처리나 윈도우 시스템의 메시지 처리기, 프로세스 관리 등 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에 이용된다.
출처: http://ko.wikipedia.org/wiki/%ED%81%90_(%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0)
라고 쓰여 있다.. 암튼 먼저 입력한넘부터 출력하기 좋은 자료구조란다.
2. 완전 간단 구현 큐 소스
암튼 그냥 선형큐 는 오버플로 가 날 문제를 안고 있는 구조라 하니 조금 수정된 원형큐로 해보자...
3. 원형큐
01.#include <string.h>02.#include <stdlib.h>03.#include <stdio.h>04.#include <ctype.h>05. 06.#define MAX 10007. 08.char *p[MAX];09.int spos = 0;10.int rpos = 0;11. 12.void push(char *q) {13. p[spos++] = q;14. spos = spos % MAX;15.}16. 17.char * pop() {18. rpos = rpos % MAX;19. return p[rpos++];20.}합병정렬
Array를 반씩 쪼갠다.
한번 쪼개면 두개의 큰 덩어리가 나올 것이다.
이렇게 나온 덩어리를 또 다시 쪼갠다.
이렇게 덩어리를 계속 쪼개다 보면, 결국 한 개의 원소가 하나의 덩어리가 된다.
이 상태에서 다시 덩어리를 뭉치는데, 그냥 뭉치는 것이 아니라
각각의 원소를 비교해 가면서 원소를 차례로 배열한다.
이런 식으로 덩어리를 계속 뭉쳐가다 보면 원래의 Array가 정렬된다.
이것이 합병 정렬의 기본 아이디어다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | #include <stdio.h> #define LEN 9 void merge_sort(int num[],int start, int end); void merge(int num[], int start, int mid, int end); void tracer(int num[],int len); int main(void){ int testArr[LEN] = {485,241,454,325,452,685,498,890,281}; merge_sort(testArr, 0, LEN-1); } void merge_sort(int num[],int start, int end){ // Array를 두개의 덩어리로 나눔 int median = (start + end)/2; // 중간값 설정 if(start < end){ // 덩어리의 원소가 하나일 때까지 merge_sort(num, start, median); merge_sort(num, median+1, end); // 각각의 덩어리로 재귀함수 호출 merge(num, start, median, end); // 각각의 덩어리를 뭉치면서 정렬 } } void merge(int num[], int start, int median, int end){ int i,j,k,m,n; int tempArr[LEN]; // 임시로 데이터를 저장할 배열 i = start; // 앞의 덩어리의 시작 Index j = median+1; // 뒤의 덩어리의 시작 Index k = start; // 임시 배열의 시작 Index while (i <= median && j <= end){ tempArr[k++] = (num[i] > num [j]) ? num [j++] : num [i++]; //작은 숫자를 찾아 임시 배열에 넣는다. 어느쪽 덩어리든 Index의 끝에 닿으면 빠져나온다. } // 아직 배열에 속하지 못한 부분들을 넣기 위한 부분 m = (i > median) ? j : i; // 아직 원소가 남아있는 덩어리가 어디인지 파악 n = (i > median) ? end : median; // 마찬가지로, for문의 끝 Index를 정하기 위함임 for (; m<=n; m++){ // 앞에서 구한 m, n으로 배열에 속하지 못한 원소들을 채워넣음 tempArr[k++] = num[m]; } for (m=start; m<=end; m++){ num[m] = tempArr[m]; // 임시 배열에서 원래 배열로 데이터 옮기기 } printf("Merging: %d ~ %d & %d ~ %d\n",start,median,median+1,end); tracer(num,LEN); } void tracer(int num[],int len){ int i; for(i=0;i<len;i++){ printf("%d\t",num[i]); } printf("\n\n"); } |
결과
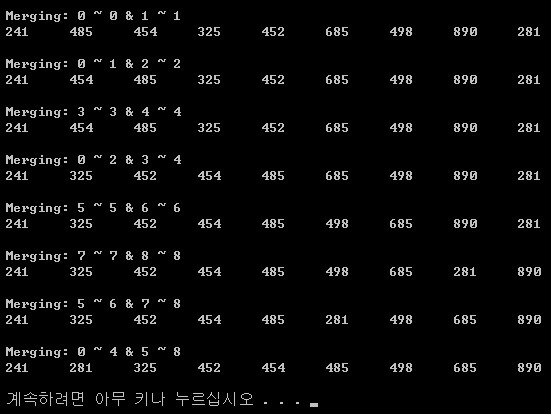
분석
위에서 9개의 원소를 가진 배열의 인덱스를 각각 0 ~ 8 이라고 했을때,
다음과 같은 덩어리로 나뉘어진다.
(((0, 1), 2), (3, 4)), ((5, 6), (7, 8))
결과에서 표시하고 있는 것은 이렇게 나뉘어진 원소들의 Index와 병합한 이후의 Array라고 할 수 있다.
퀵정렬
퀵 정렬의 기본 아이디어는,
기준이 되는 숫자를 정해서 그것보다 큰 원소들과 작은 원소들로 편을 갈라놓고 정렬하자는 것이다.
이 아이디어를 따라가기 위해서는 기준이 되는 숫자를 어떻게 정할 것인가,
그리고 큰 원소들과 작은 원소들을 어떻게 분리해 둘 것인가 하는 것이 주요 목표가 될 것이다.
백마디 설명 보다는 역시 예제를 하나 꺼내는 것이 좀 더 설명하기 쉬울 것 같다.
45, 39, 98, 15, 52, 44, 33, 28, 40, 38, 77, 68, 11, 43
기준이 되는 숫자를 Pivot 이라고 부르는데,
맨 앞에 있는 숫자를 Pivot으로 삼을수도 있고, 정 가운데 있는 숫자를 Pivot으로 삼을 수도 있다.
사실 어떤 숫자를 Pivot으로 하든 상관이 없다.
이 예제에서는 임의로 정 가운데(?) 있는 33이라는 숫자를 택해보겠다.
45, 39, 98, 15, 52, 44, 33, 28, 40, 38, 77, 68, 11, 43
우리는 양쪽 끝에서부터 각각의 원소를 하나하나 확인할 것이다.
왼쪽에서 접근하는 인덱스를 i,
오른쪽에서 접근하는 인덱스를 j라고 하자.
왼쪽에서 접근하는 인덱스는 33 보다 크거나 같은 경우에 멈추고,
오른쪽에서 접근하는 인덱스는 33 보다 작거나 같은 경우에 멈춘다.
그렇다면 i는 시작하자마자 45에서 멈추고, j는 11에서 멈추게 된다.
이렇게 되는 경우 두개의 원소를 맞교환한다.
11, 39, 98, 15, 52, 44, 33, 28, 40, 38, 77, 68, 45, 43
계속 접근을 하다 보면, 아래와 같이 교환이 계속 된다.
11, 28, 98, 15, 52, 44, 33, 39, 40, 38, 77, 68, 45, 43
11, 28, 33, 15, 52, 44, 98, 39, 40, 38, 77, 68, 45, 43
계속 접근을 하다보면 i는 52에서 멈출 것이고 j는 15에 도착하게 되는데,
i보다 j가 작아지는 경우에는
j가 있는 위치와 Pivot의 숫자를 맞교환 해준다.
즉, 위의 예제에서는 15와 33을 맞교환한다.
11, 28, 15, 33, 52, 44, 98, 39, 40, 38, 77, 68, 45, 43
이렇게 하면 Pivot 인 33의 왼쪽 편에는 33보다 작거나 같은 숫자,
오른 편에는 33보다 크거나 같은 숫자가 위치하게 된다.
이렇게 해서 생긴 두개의 편에서 각각 다시 Quick Sort를 한다.
이렇게 계속 해서 정렬하면서, 정렬하려는 원소가 한 개가 될 때까지 정렬하면 정렬이 완료되는 방식이다.
* 수정된 내용
다만 pivot은 정렬대상에서 제외되어야 하는데,
pivot을 중간에서 설정하는 경우에는 이 점에 대해서 고려해야 하므로 추가적인 코드가 필요하다.
따라서 아래에는 맨 첫번째 원소를 pivot으로 설정한뒤, 나머지 뒷 부분의 array들을 정렬하고,
pivot과 j를 맞교환 함으로써 sorting을 마친다.
* 수정된 내용
다만 pivot은 정렬대상에서 제외되어야 하는데,
pivot을 중간에서 설정하는 경우에는 이 점에 대해서 고려해야 하므로 추가적인 코드가 필요하다.
따라서 아래에는 맨 첫번째 원소를 pivot으로 설정한뒤, 나머지 뒷 부분의 array들을 정렬하고,
pivot과 j를 맞교환 함으로써 sorting을 마친다.
코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | #include <stdio.h> #define LEN 9 void quick_sort(int num[],int start, int end); void tracer(int num[],int len); int main(void){ int testArr[] = {485,241,454,325,452,685,498,890,281}; quick_sort(testArr, 0, LEN-1); // 퀵 정렬 함수 호출 } void quick_sort(int num[],int start, int end){ int i,j,p; int tempValue; // 스왑 임시 저장소 if (start < end) { i = start+1; // 양끝에서 접근할 값 정의 j = end; p = num[start]; // pivot을 맨 처음 값으로 설정 do { while (num[i] < p){ i++; // pivot보다 크거나 같은 값 만날 때까지 }; while (num[j] > p) { j--; // pivot보다 작거나 같은 값 만날 때까지 } // 구한 i, j 인덱스의 값을 서로 스왑 if (i < j){ tempValue = num[j]; num[j] = num[i]; num[i] = tempValue; } } while (i < j); // i보다 j가 클때만 동작 num[start] = num[j]; num[j] = p; printf("[start Index: %d, end Index: %d, Pivot: %d]\n",start,end,p); // pivot값 프린트 tracer(num,LEN); // Array 전체 프린트 quick_sort(num,start,j-1); // 왼쪽 편 같은 방법으로 sorting quick_sort(num,j+1,end); // 오른쪽 편 같은 방법으로 sorting } } void tracer(int num[],int len){ int i; for(i=0;i<len;i++){ printf("%d\t",num[i]); } printf("\n\n"); } |
결과
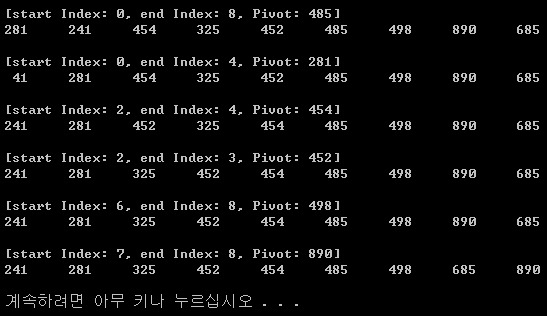
분석
첫번째 줄에서 첫번째 숫자인 485가 Pivot이 되며,
왼편에는 485보다 작거나 같은 숫자, 오른편에는 485보다 크거나 같은 숫자가 위치한다.
두번째 경우에는 왼편의 5개 숫자에 대해서만 퀵 정렬을 시작하게 되고,
Pivot을 281로 설정하고, 마찬가지로 정렬을 한다.
나머지 경우에 대해서도 마찬가지로 정렬을 수행하면, 최종적으로 오름차순 정렬이 끝나게 된다.
버블 정렬
버블정렬(bubble sort)이란?교환정렬이라고도 하며 정렬이 진행되는 모양이 비누거품(bubble)과 같다고 하여 붙여진 이름이다. 나란히 있는 두개의 데이터를 계속하여 바꾸어 나간다.
버블정렬 과정
1. 우선 맨 처음에 모든 원소들의 최대값을 찾으려면 맨 처음 원소와 둘째 원소를 비교한다. 만약 앞
의 원소가 뒤의 원소보다 크면 두 원소의 자리를 바꾼다.
2. 둘째 원소와 셋째 원소를 비교해 자리를 바꾼다.
3. 이 과정을 마지막 원소까지 반복하면 맨 마지막 자리에 제일 큰 원소가 자리잡게 된다.4. 최대값을 가진 원소를 제외하고 나머지에 대해서 이 과정을 반복하면 그 다음으로 큰 원소를 찾
아내 마지막에서 둘째 자리에 넣게 된다.5. 과정을 끝까지 반복하면 모든 원소가 오름차순으로 정리된다.
아래는 기본적인 버블정렬의 소스코드이다.
void Bubble(int item[], int count)버블 정렬의 예와 각 단계 진행 과정
{
register int i, j, temp;
for(i=0; i<count-1; i++) {
for(j=0; j<count-i-1; j++) {
// 오름차순이 되게 비교를 하여 데이터 교환
if(item[j] > item[j+1]) {
temp = item[j];
item[j] = item[j+1];
item[j+1] = temp;
}
}
}
}
/* list에 대한 기본 버블정렬 알고리즘 */데이터 15 4 8 3 50 9 20
void bubble_sort(element list[], int n)
{
int i, j;
element next;
for(i = n-1; i > 0; i--)
{ /*1*/
for(j = 0; j < i; j++)
{ /*2*/
if(list[j] > list[j + 1]
{ /*3*/
swap(list[j], list[j + 1]);
}
}
}
}
1단계 4 8 3 15 9 20 50 2단계 4 3 8 9 15 20 50
3단계 3 4 8 9 15 20 50
4단계 3 4 8 9 15 20 50
1 단계 list[i]와 list[i+1]를 i = 0,1,2, ···, n-2에 대하여 비교하여 만약 뒤 데이터가 값이 더 작으면 바꾼다
(swap list[i]와 list[i+1]) 이 과정을 거치면 가장 큰 값이 맨 뒤로 이동한다.
2 단계 list[i]와 list[i+1]를 i = 0,1,2, ···, n-3에 대하여 비교하여 만약 뒤 데이터가 값이 더 작으면 바꾼다
(swap list[i]와 list[i+1]) 이 과정을 거치면 두 번째 큰 값이 뒤에서 두 번째에 위치한다.
3 단계 list[i]와 list[i+1]를 i = 0,1,2, ···, n-4에 대하여 비교하여 만약 뒤 데이터가 값이 더 작으면 바꾼다
(swap list[i]와 list[i+1]) 이 과정을 거치면 세 번째 큰 값이 뒤에서 세 번째에 위치한다.
n-1단계list[i]와 list[i+1]를 i = 0에 대하여 비교하여 만약 뒤 데이터가 값이 더 작으면 바꾼다
(swap list[i]와 list[i+1]) 이 과정을 거치면 n-1번째 큰 값이 뒤에서 n-1번째에 위치한다.
버블정렬 프로그램의 분석
단계 | 첨자변화 | 비교횟수 |
1단계 | i=n-1 : j=0,1,2,…,n-2 | n-1번 |
2단계 | i=n-2 : j=0,1,2,…,n-3 | n-2번 |
3단계 | i=n-3 : j=0,1,2,…,n-4 | n-3번 |
... ... | ||
n-2단계 | i=2 : j=1,0 | 2번 |
n-1단계 | i=1 : j=0 | 1번 |
비교 횟수로 따지면 수행시간 복잡도는 O(n(n-1)/2 ) = O(n의 거듭제곱)이다.
n에 관한 2차 함수로 프로그램 수행 시간이 걸린다.
피드 구독하기:
글 (Atom)